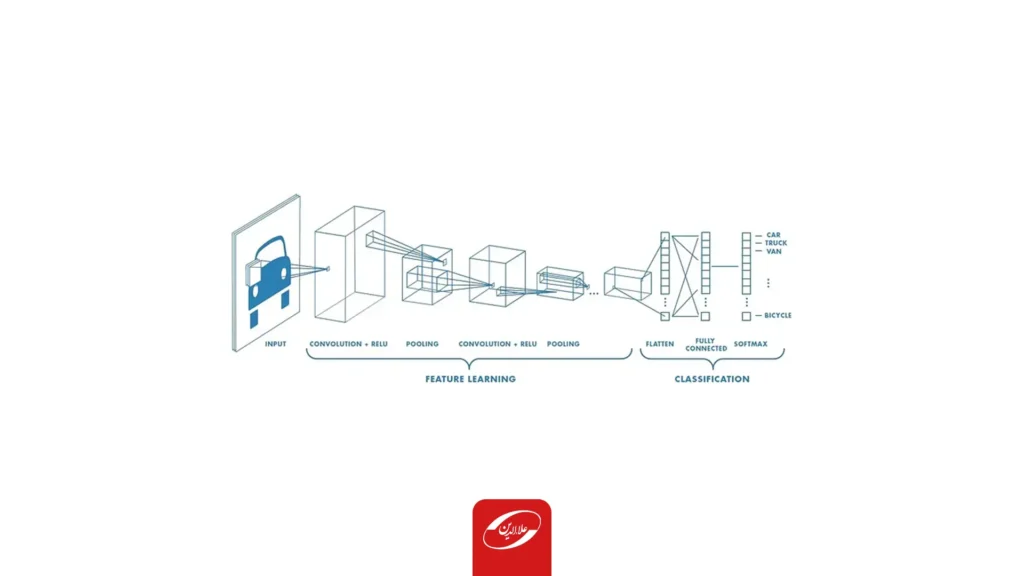
شبکههای عصبی پیچشی یا کانولوشنی بهعنوان یکی از پیشرفتهترین ابزارهای پردازش تصویر، با ترکیب عملیات کانولوشن و لایههای پولینگ، انقلابی در درک و تحلیل دادههای تصویری ایجاد میکنند.
هوش مصنوعی در حال تجربه رشد بیسابقهای در کاهش فاصله بین تواناییهای انسان و ماشین است. پژوهشگران و علاقهمندان به این حوزه، روی جنبههای مختلف این علم کار میکنند تا دستاوردهای شگفتانگیزی را رقم بزنند که یکی از این زمینههای گسترده، شبکههای عصبی کانولوشنی بینایی کامپیوتر است.
هدف حوزه هوش مصنوعی، توانمندسازی ماشینها برای درک انسانی و استفاده از این دانش برای انجام وظایف متعددی مانند شناسایی تصویر و ویدئو، تحلیل و طبقهبندی تصاویر، بازآفرینی رسانهها، سامانههای توصیهگر، پردازش زبان طبیعی و چندین مورد دیگر است. پیشرفتهای بینایی کامپیوتر با یادگیری عمیق ماشینی اصولا حول الگوریتمی خاص تحتعنوان شبکههای عصبی کانولوشنی (Convolutional Neural Network) توسعه یافته و بهبود مییابند.
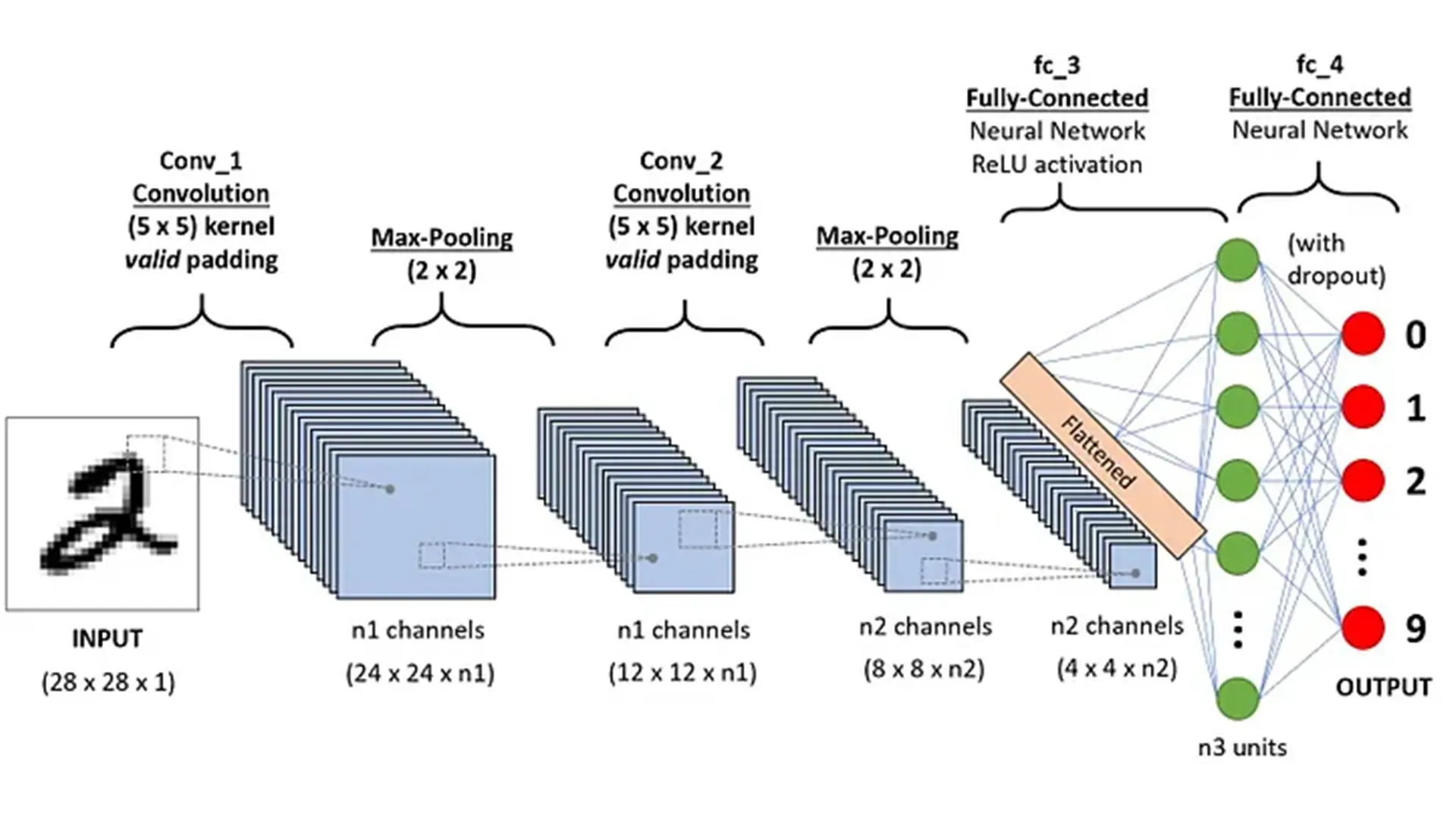
شبکه عصبی کانولوشنی (ConvNet/CNN) یک الگوریتم یادگیری عمیق ماشینی است که میتواند تصویر ورودی را پردازش کرده، به جنبهها یا اشیای مختلف در آن اهمیت دهد (از طریق وزنها و بایاسهای قابل یادگیری) و آنها را از یکدیگر متمایز کند. پیشپردازش موردنیاز در ConvNet بهصورت چشمگیری کمتر از سایر الگوریتمهای طبقهبندی شدهاست. در روشهای اولیه فیلترها بهشکل دستی طراحی میشدند، اما شبکههای عصبی پیچشی با آموزش کافی قادر به یادگیری فیلترها و ویژگیها هستند.
معماری ConvNet از الگوی ارتباطی نورونها در مغز انسان الهام گرفتهشده و برپایه ساختار قشر بینایی طراحی شده است. نورونهای منفرد تنها به محرکهایی پاسخ میدهند که در ناحیه محدود و خاصی از میدان بینایی قرار دارند که به آن میدان گیرنده گفته میشود؛ مجموعهای از این میدانها بهصورت همپوشانی کل ناحیه بینایی را پوشش میدهند.
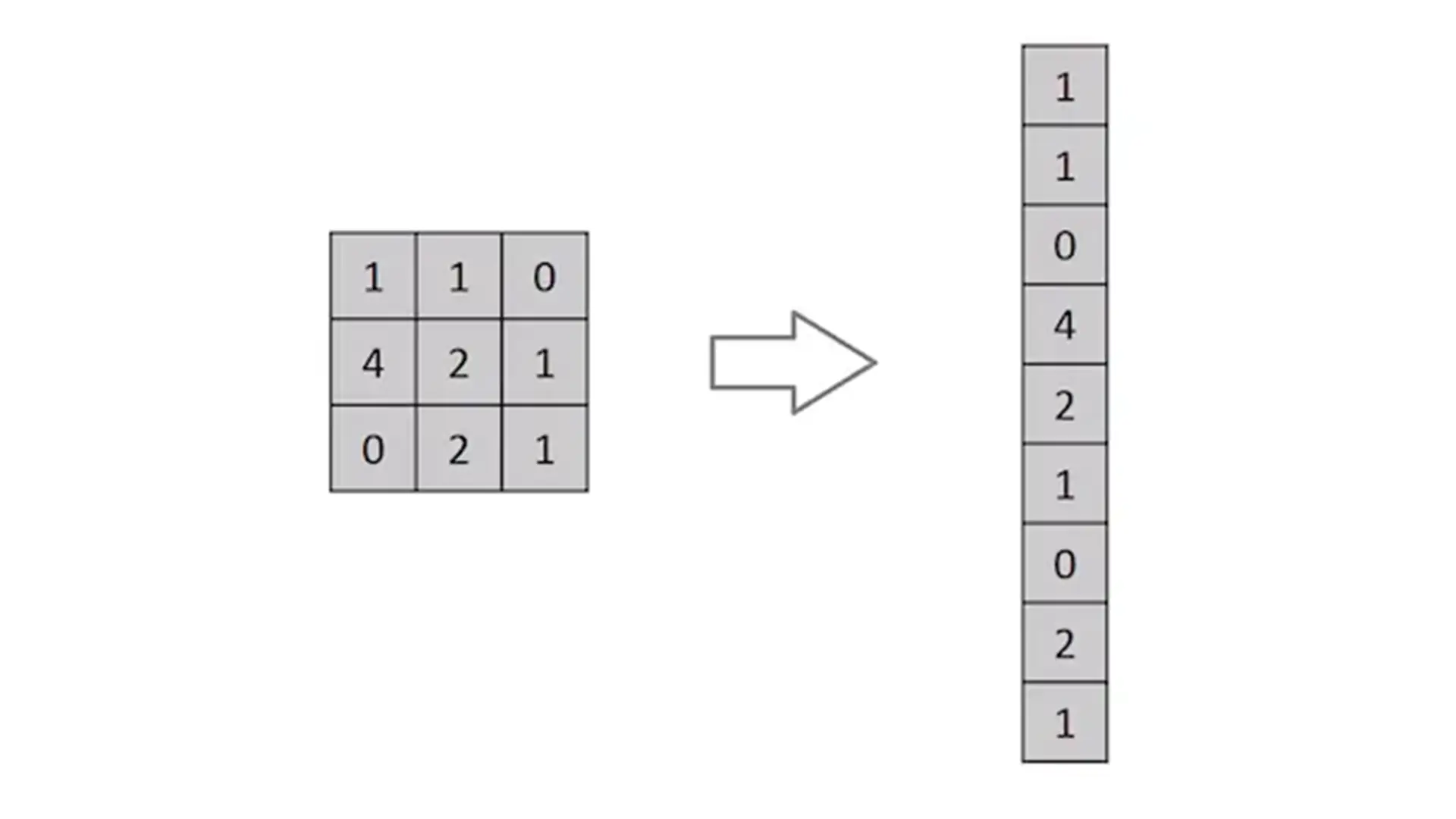
تصاویر در واقع چیزی جز ماتریسی از مقادیر پیکسلها نیستند، اما چرا تصویر را بهصورت مسطح تبدیل نکنیم و برای طبقهبندی به یک شبکه پرسپترون چندلایه (MLP) ارائه ندهیم؟ پاسخ آناستکه روش یادشده در تصاویر بسیار ساده، احتمالا دقتی متوسط داشته باشد، اما در تصاویر پیچیده با وابستگیهای پیکسلی فراوان دقت بسیار پایینی ارائه میدهد.
شبکه عصبی پیچشی میتواند وابستگیهای مکانی و زمانی موجود در تصویر را ازطریق اعمال فیلترهای مناسب ثبت کند. مهندسان میگویند این معماری بهدلیل کاهش تعداد پارامترهای درگیر و قابلیت استفاده مجدد از وزنها، تطابق بهتری با مجموعه دادههای تصویری دارد؛ بهاینمعنی که شبکه میتواند پیچیدگیهای تصویر را بهتر درک کند.
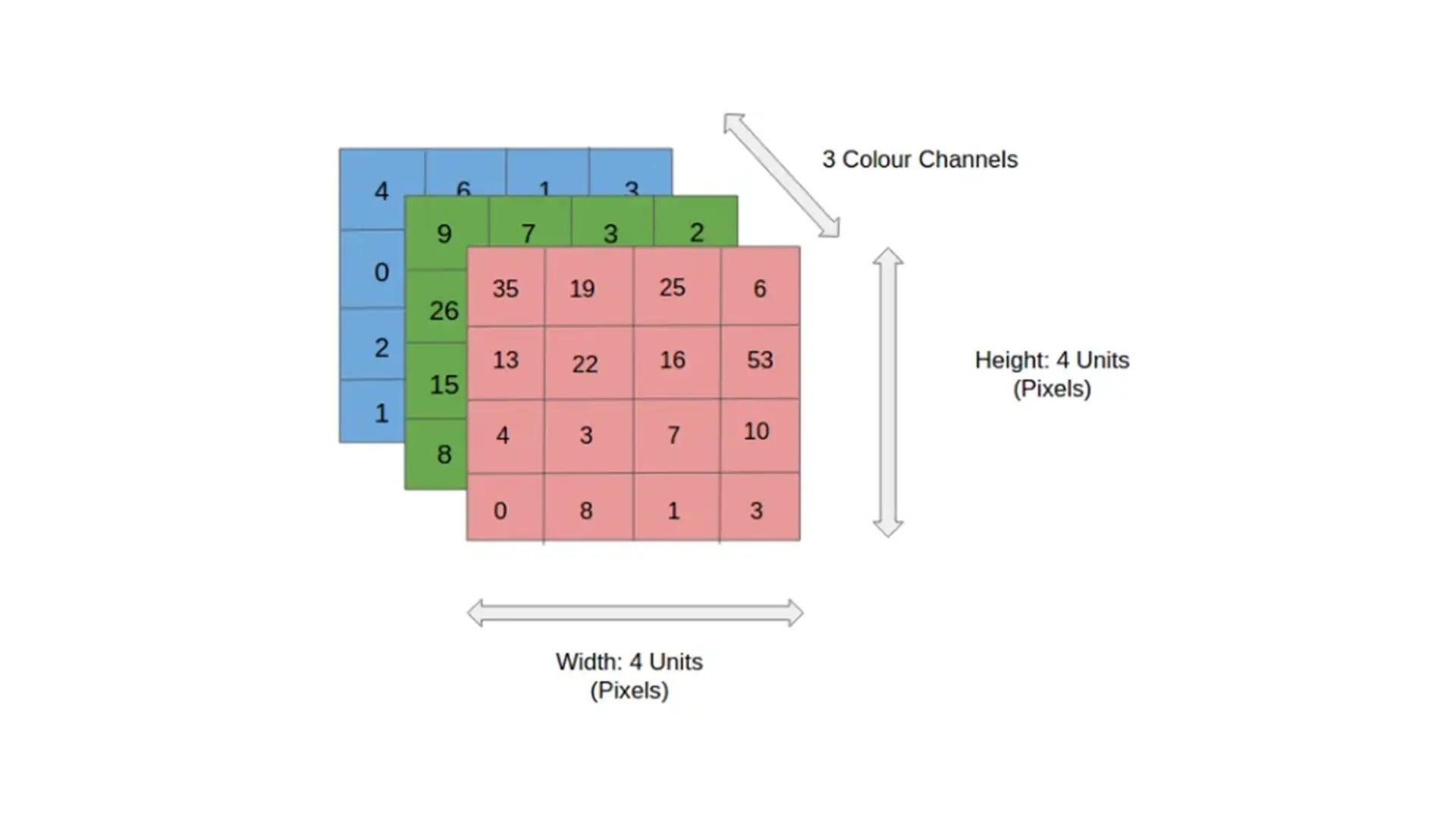
تصاویر دیجیتالی در فضاهای رنگی متنوعی مانند خاکستری، RGB و HSV تعریف میشوند. برای مثال، در یک تصویر RGB، سه لایه رنگی قرمز، سبز و آبی بهصورت جداگانه وجود دارند. حال اگر تصاویر به ابعاد بسیار بزرگ مانند 8K (7680×4320) برسند، حجم محاسباتی مورد نیاز برای پردازش آن ها به شکل قابلتوجهی افزایش خواهد یافت. چالش موردنظر اهمیت استفاده از معماریهای مختلف مانند شبکههای عصبی کانولوشنی (ConvNet) را آشکار میسازد.
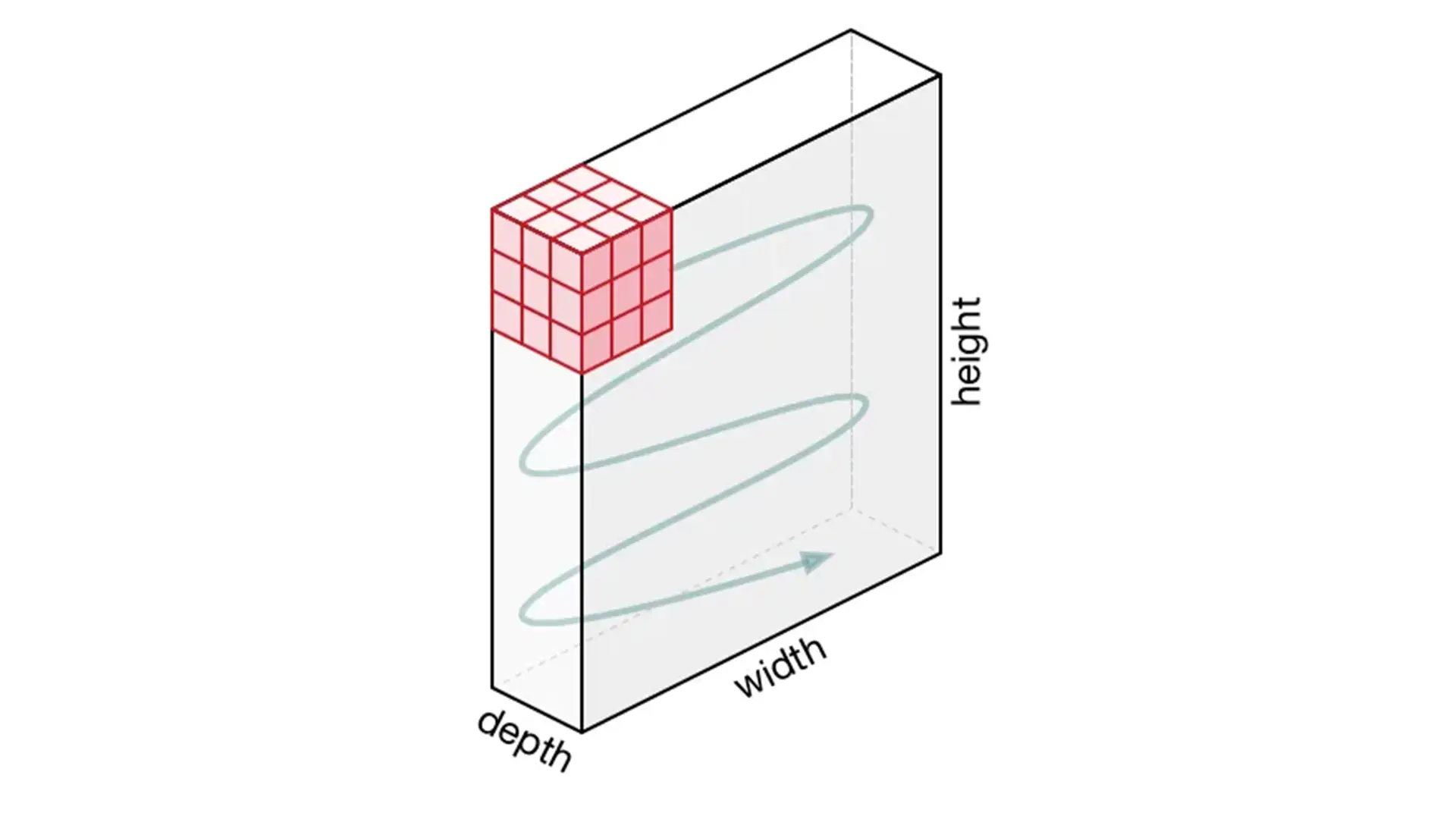
نقش اصلی ConvNet در سادهسازی تصاویر و تبدیل آنها به فرمتی قابلپردازش است، بدون آنکه ویژگیهای کلیدی و حیاتی برای پیشبینی دقیق از بین بروند؛ این موضوع بهویژه زمانی اهمیت پیدا میکند که معماری موردنظر باید از قدرت بالایی در یادگیری ویژگیها برخوردار باشد و بتواند به دادههای حجیم تعمیم یابد. برای درک بهتر این فرآیند، فرض کنید تصویری با ابعاد زیر داریم که نشاندهنده ارتفاع، عرض و تعداد کانالهای تصویر هستند.
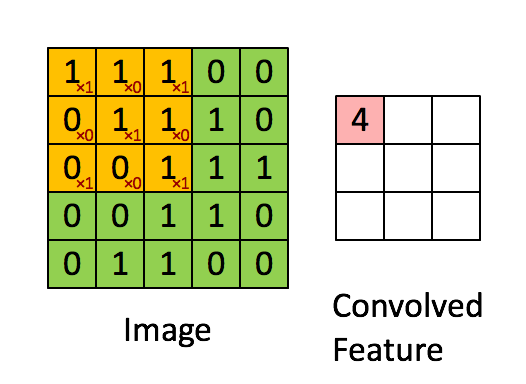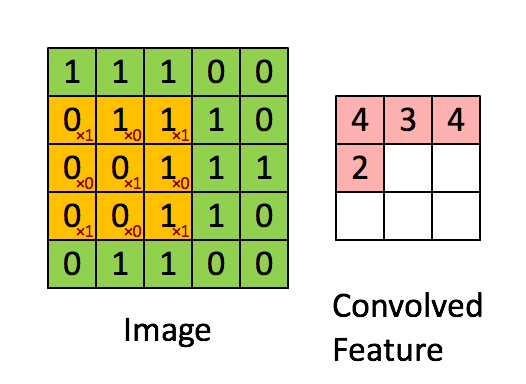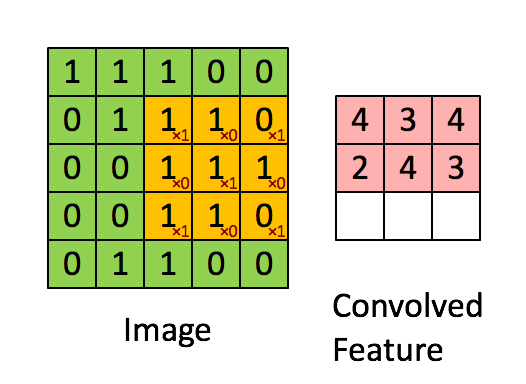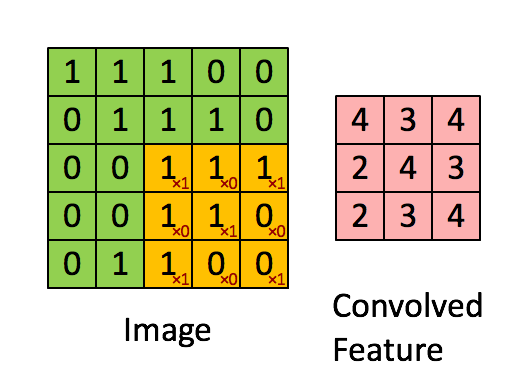
در این مثال، بخش سبز تصویر ورودی با ابعاد 5×5×15 نشان داده شده است؛ در اولین مرحله پردازش توسط لایه کانولوشنی، عنصری به نام هسته یا فیلتر (Kernel/Filter) عملیات پیچش را روی تصویر انجام میدهد. این هسته در اینجا بهصورت یک ماتریس 3×3×1 تعریف شده که با رنگ زرد مشخص شده است.
Kernel/Filter, K =
1 0 1
0 1 0
1 0 1علاوهبراین، هسته (K) با طول گام (Stride) برابر یک تعریف شده؛ بنابراین ۹ بار روی تصویر جابهجا میشود. در هر جابهجایی، یک ضرب عنصر به عنصر (ضرب هادامارد) بین هسته و بخشی از تصویر که در آن لحظه زیر هسته قرار دارد، انجام میشود. پس از اتمام پردازش یک ردیف از تصویر، فیلتر به ابتدای ردیف بعدی بازمیگردد و این فرآیند را تا پایان تصویر ادامه میدهد تا تمامی نواحی پیمایش شوند.
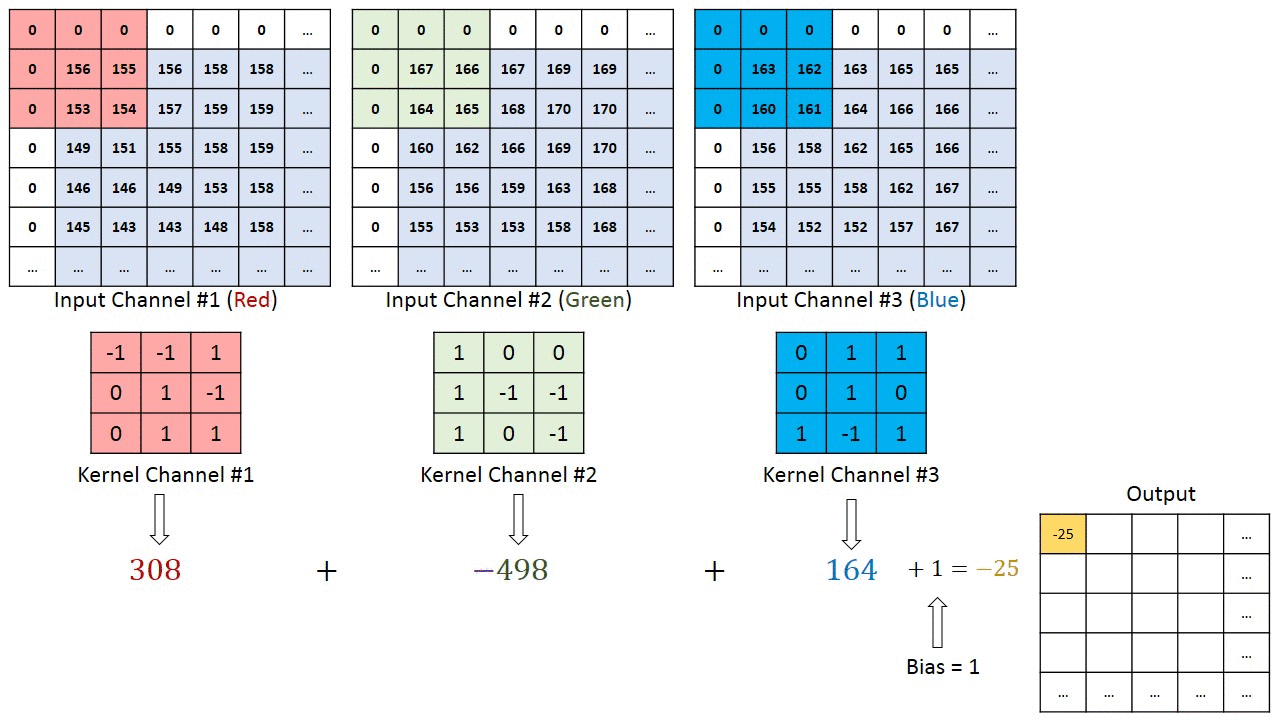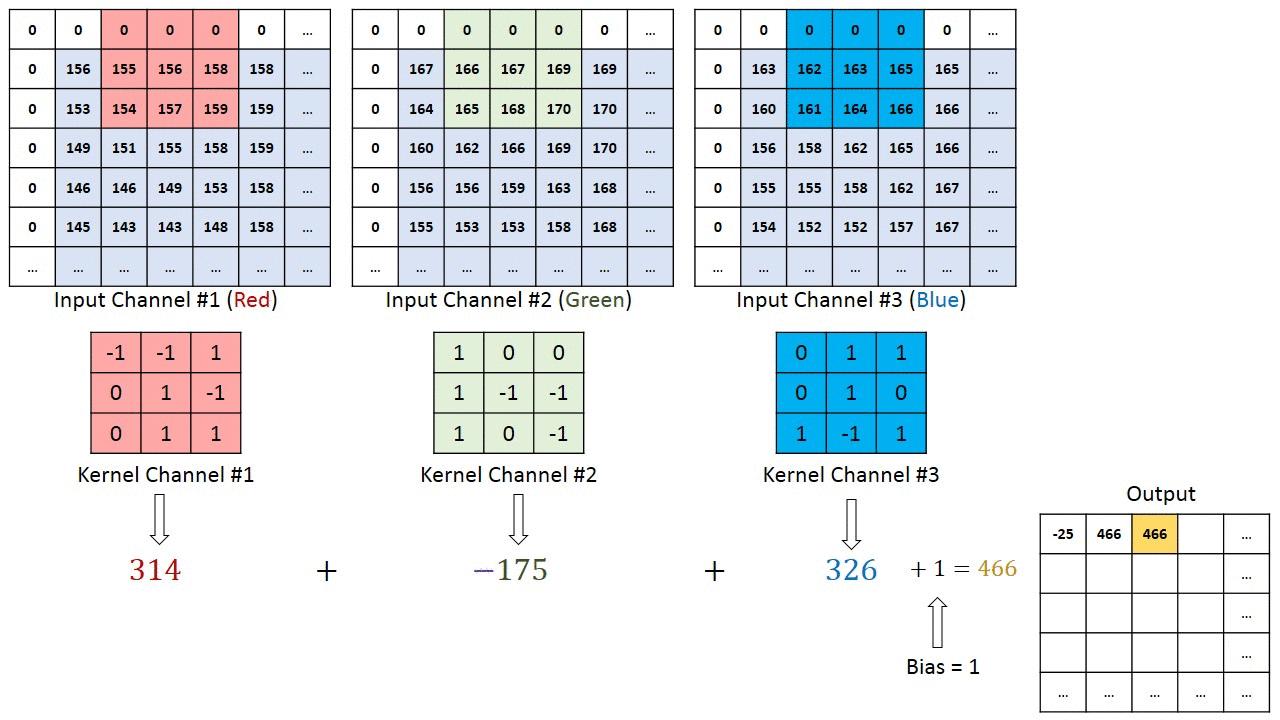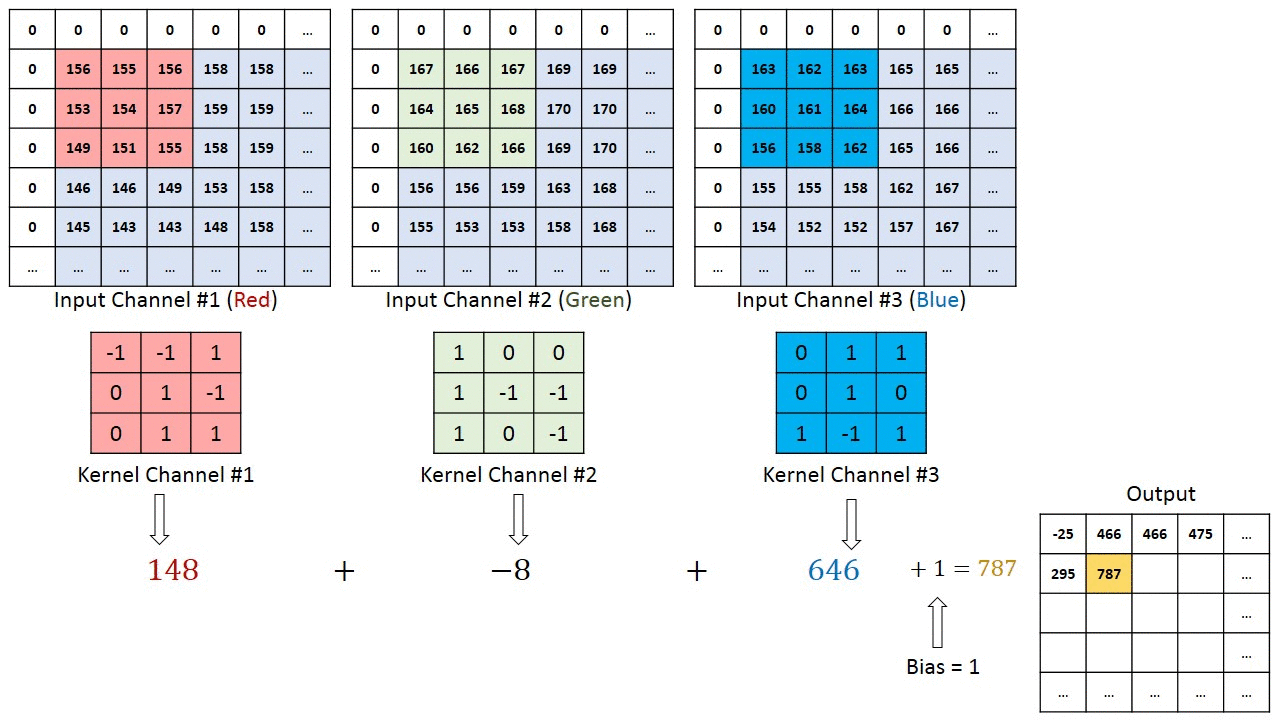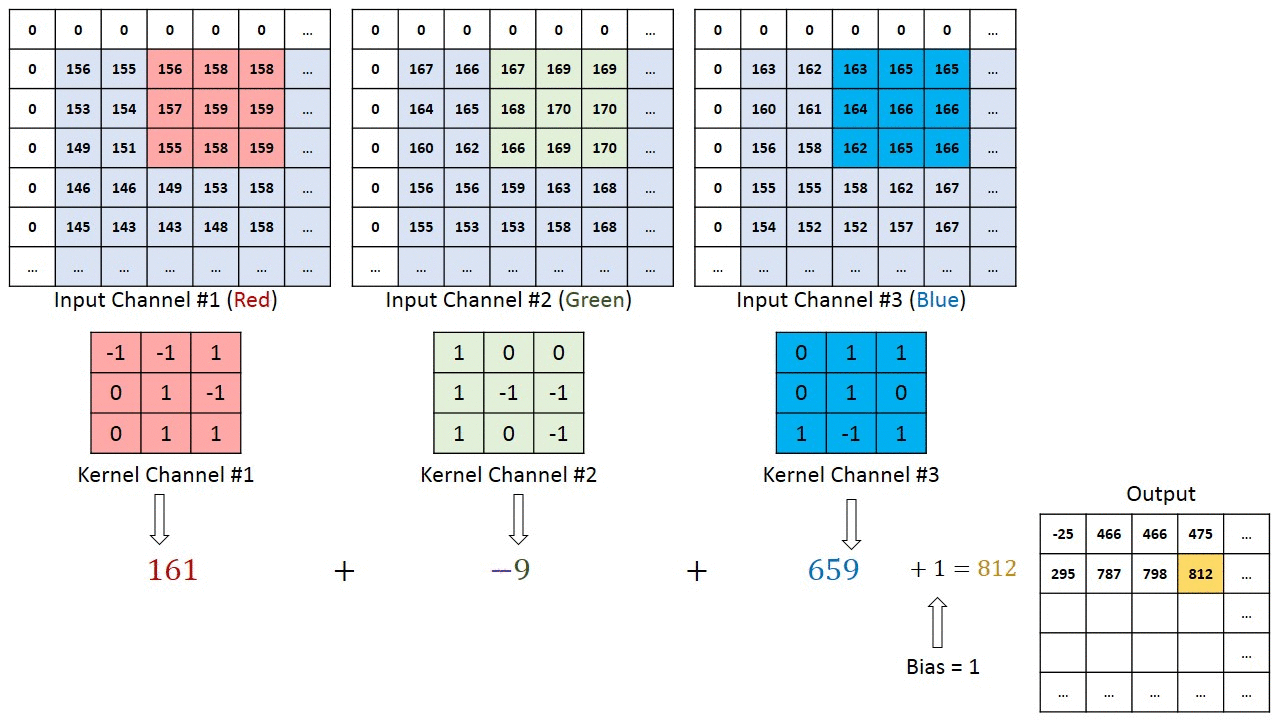
شبکههای عصبی پیچشی (ConvNets) از مهمترین معماریها در یادگیری عمیق هستند که برای پردازش تصاویر به کار میروند. در این نوع شبکهها، عمق هسته (Kernel) با عمق تصویر ورودی برابر است. در این ساختار، ضرب ماتریسی بین کانالهای متناظر هسته و تصویر ورودی انجامشده و نتایج حاصل پس از جمع شدن با مقدار بایاس، به خروجی با عمق یک کانال تبدیل میشود که ویژگیهای پیچیدهای از تصویر را بهنمایش میگذارد.
عملیات کانولوشن بهمنظور استخراج قابلیتهای سطح بالا از تصویر ورودی انجام میشود؛ بنابراین، ویژگیها میتوانند شامل لبهها، رنگها و جهتگیری گرادیانها باشند. اولین لایه کانولوشنی وظیفه استخراج ویژگیهای سطح پایین را برعهده دارد، اما با افزایش تعداد لایهها، شبکه میتواند ویژگیهای سطح بالاتری را نیز شناسایی کند؛ این فرآیند، درک مدل از تصاویر را مشابه با نحوه درک انسان بهبود میبخشد.
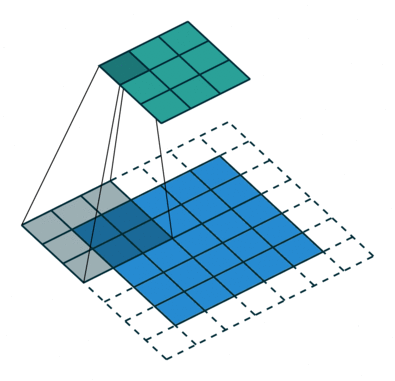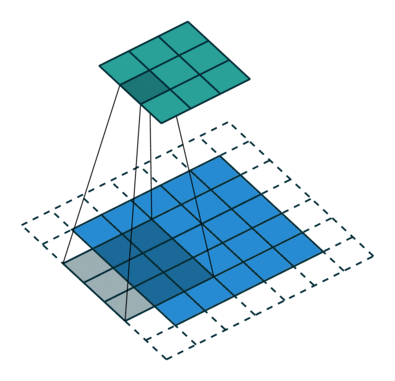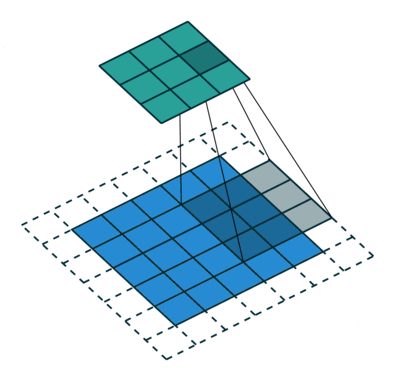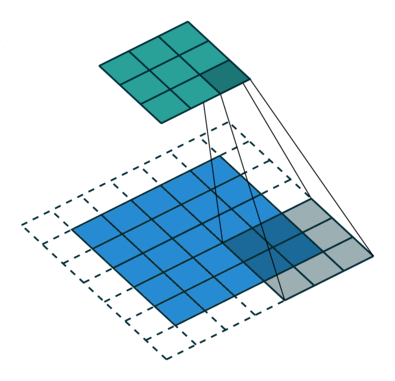
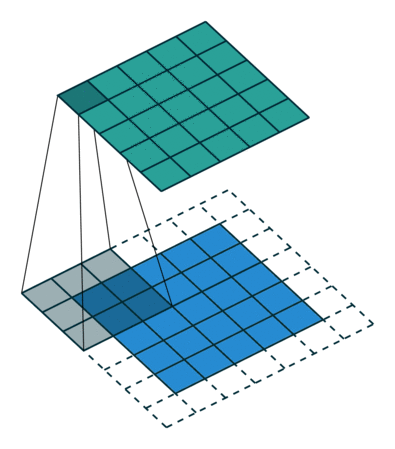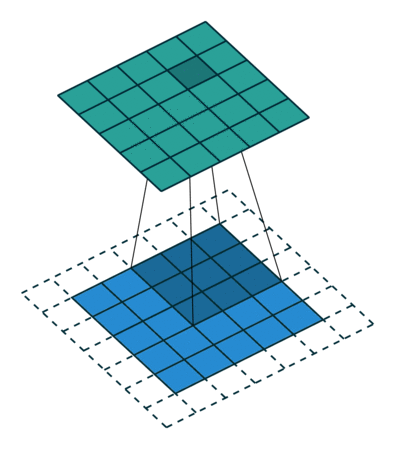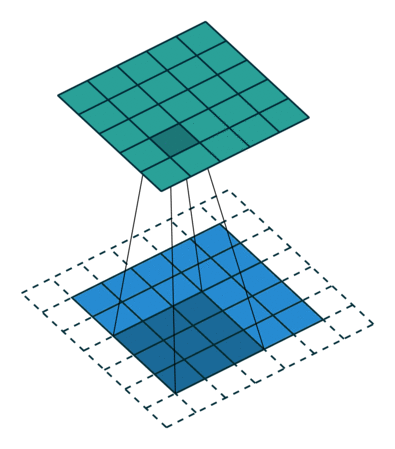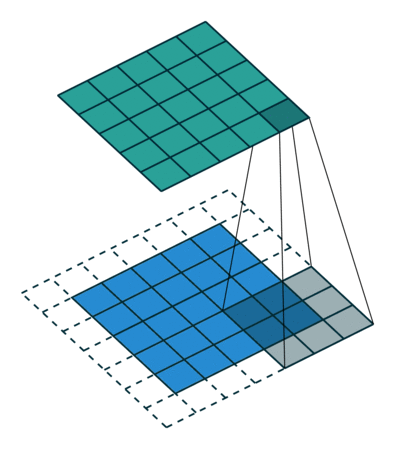
نتایج عملیات کانولوشن براساس نوع پدینگ به دو دسته تقسیم میشوند:
- پدینگ معتبر (Valid Padding): در این روش، هیچ پدینگی به تصویر ورودی اضافه نمیشود و خروجی ابعاد کوچکتری نسبتبه تصویر ورودی خواهد داشت.
- پدینگ یکسان (Same Padding): در این روش، ابعاد تصویر ورودی حفظ میشود؛ مثلا اگر یک هسته 3×3×1 روی تصویر 5×5×1 اعمال شود، خروجی نهایی با استفاده از پدینگ یکسان، همچنان ابعاد 5×5×1 خواهد داشت.
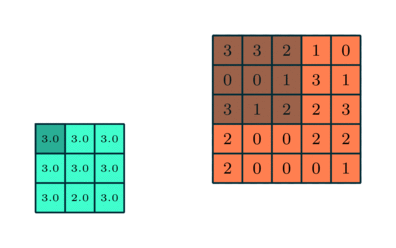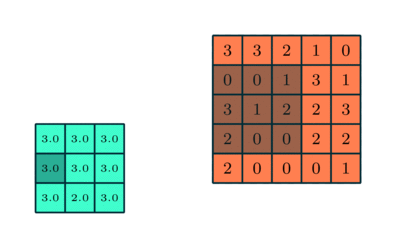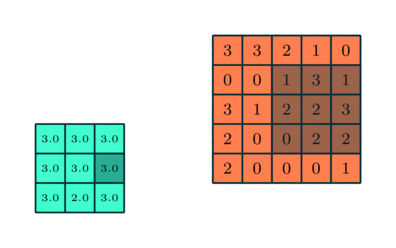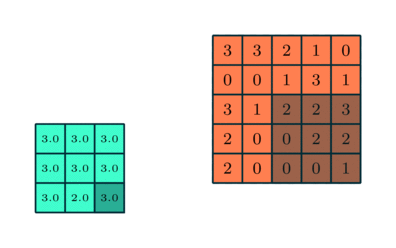
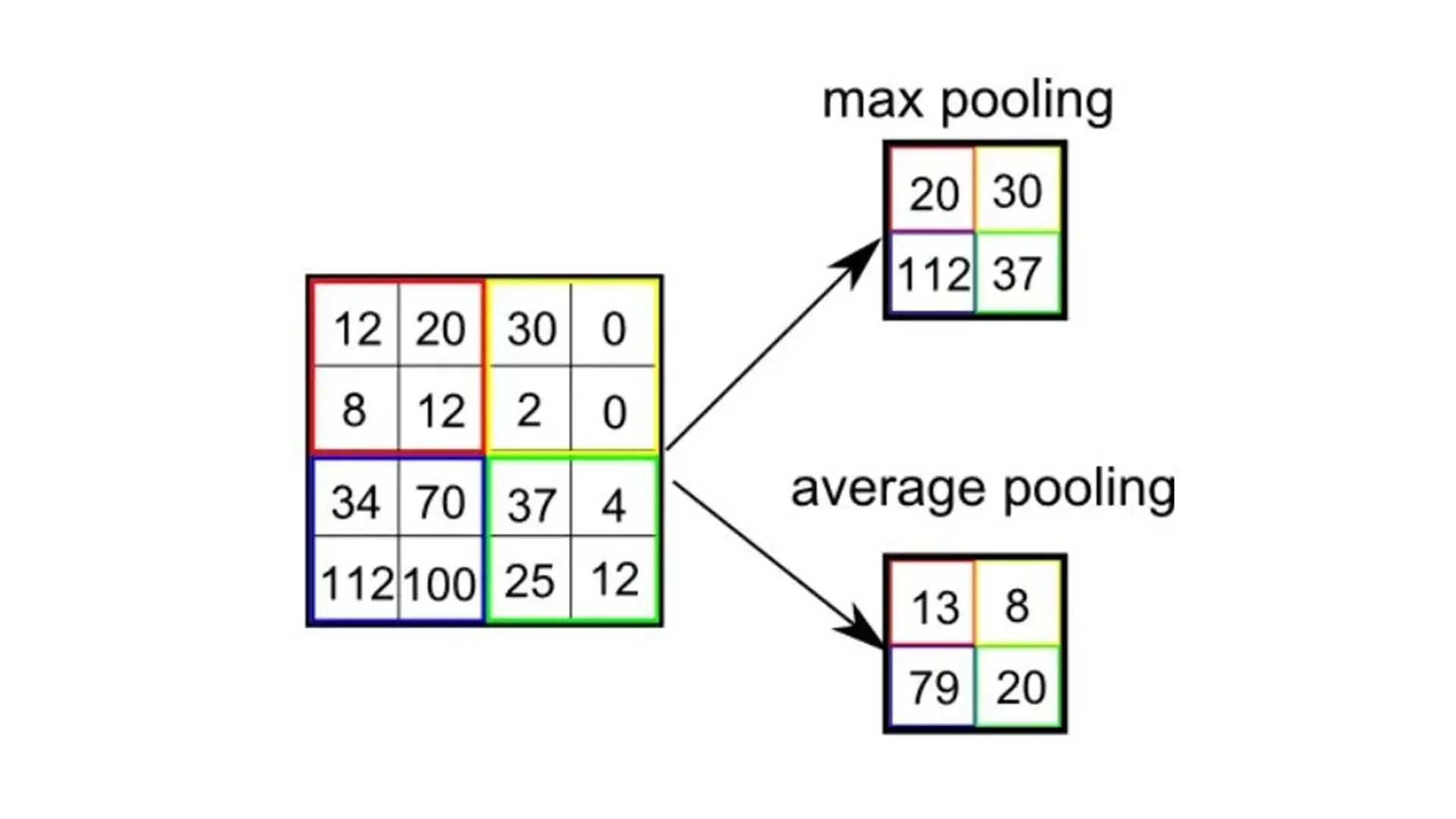
در شبکههای عصبی پیچشی، لایه پولینگ (Pooling) نیز به اندازه لایه کانولوشنی اهمیت دارد. هدف لایه پولینگ کاهش اندازه فضایی ویژگیهای پیچیده شده تا قدرت محاسباتی موردنیاز برای پردازش دادهها کاهش یابد. همچنین، این لایه ویژگیهای غالبی را استخراج میکند که درمقایسهبا چرخش و موقعیت مقاوم هستند و بنابراین بهصورت موثر به فرآیند آموزش مدل کمک میکند.
- پولینگ بیشینه (Max Pooling): بیشترین مقدار از ناحیه مورد نظر را انتخاب کرده و در حذف نویز و استخراج ویژگیهای غالب بهتر عمل میکند.
- پولینگ میانگین (Average Pooling): میانگین مقادیر ناحیه را محاسبه میکند و بیشتر برای کاهش ابعاد استفاده میشود.
پولینگ بیشینه بهعنوان یک سرکوبکننده نویز عمل میکند، چراکه فعالسازیهای نویزی را حذفکرده و درکنار کاهش ابعاد، فرآیند حذف نویز را نیز انجام میدهد. ازطرفدیگر، پولینگ میانگین تنها به کاهش ابعاد به عنوان مکانیزمی برای حذف نویز اکتفا میکند. بنابراین میتوان گفت که پولینگ بیشینه عملکرد بهتری نسبت به پولینگ میانگین دارد.
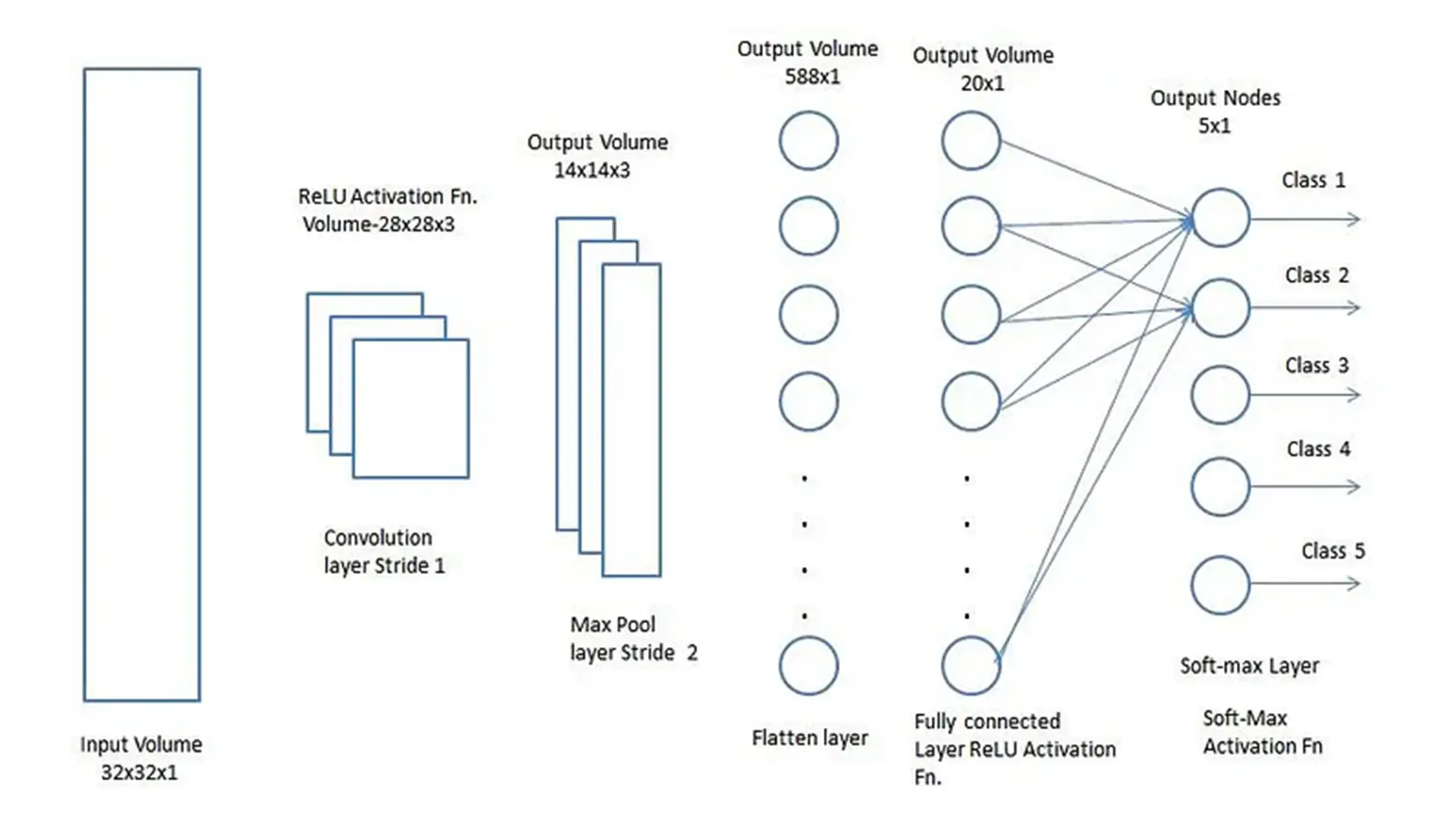
پساز عبور از لایههای کانولوشنی و پولینگ، خروجی نهایی به فرم مسطح (Flatten) تبدیل شده و به شبکه عصبی معمولی یا لایه کاملا متصل (Fully-Connected Layer) وارد میشود. لایه مسطح ترکیبات غیرخطی ویژگیهای سطح بالا را یاد میگیرد و نقش مهمی در فرآیند طبقهبندی ایفا میکند.
در انتها، تصویر ورودی که به یک بردار ستونی تبدیل شده، به شبکه عصبی پیشخور تغذیه میشود. الگوریتم پسانتشار خطا (Backpropagation) با هدف بهینهسازی مدل، در هر تکرار آموزشی اعمال میشود. ازاینسو، مدل با استفاده از تابع سافتمکس (Softmax) قادر به طبقهبندی تصاویر خواهد بود.
شبکههای عصبی پیچشی با معماریهای متنوعی توسعه یافتند که هریک نقش مهمی در پیشرفت الگوریتمهای هوش مصنوعی داشتند که از مهمترین معماریها میتوان به موارد زیر اشاره کرد:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet



